
Data Structures
Data structure is a way of organizing and storing data in a computer program so that it can be accessed and manipulated efficiently. It is a fundamental concept in computer science that is used to store and manage large amounts of data.
Data structure plays a critical role in computer programming and is a fundamental concept in software development.
Why Do We Need Data Structures ?
- Organization of Data : In programming, managing and organizing data is essential for efficient computation and analysis. Data structures provide a systematic way to store and retrieve information, ensuring that data is arranged in a manner conducive to the specific needs of the application.
- Optimized Operations : Different data structures are designed for specific types of operations. For instance, arrays excel in constant-time access, linked lists facilitate dynamic insertions and deletions, and trees enable efficient searching and sorting. Choosing the right data structure allows developers to optimize the performance of algorithms for particular tasks.
- Memory Management : Data structures play a crucial role in memory management. They enable efficient utilization of memory resources, preventing unnecessary waste and ensuring that the available memory is used in an organized and structured manner. This is particularly important in resource-constrained environments.
- Algorithm Design : Algorithms are the heart of computer programs, and the choice of data structure significantly influences algorithm design. Well-designed data structures enable the development of algorithms that are not only correct but also efficient and scalable. The efficiency of an algorithm often depends on the appropriate selection and utilization of data structures.
- Problem Solving : Real-world problems often involve complex relationships and patterns within data. Data structures provide a means to model these relationships and efficiently solve problems. Whether it's searching for an item in a database, sorting a list of elements, or representing hierarchical relationships, data structures provide the tools needed for effective problem-solving.
- Resource Efficiency : Efficient use of resources, such as time and space, is a critical consideration in software development. Data structures contribute to resource efficiency by enabling operations to be performed in the most time- and memory-efficient manner possible. This is particularly important in scenarios where processing power and memory are limited.
- Code Reusability and Maintainability : Well-designed data structures enhance code reusability and maintainability. Abstracting complex data interactions into structured and reusable components allows developers to write modular and maintainable code. This makes it easier to understand, extend, and modify codebases over time.
Different Types of Data Structure











Advantages of Using Data Structures
- Efficient data access: Data structure enables fast and efficient data access, making it easier to retrieve and manipulate data.
- Data organization: Data structure helps to organize data in a logical and structured manner, making it easier to manage and manipulate.
- Memory management: Data structure helps to manage memory effectively, reducing the risk of memory leaks and other memory-related problems.
- Improved performance: The use of data structure helps to improve the performance of the program by reducing the time taken to access and manipulate data.
There are two main types of data structures: linear data structure and non-linear data structure.
Linear Data Structure
Linear data structures are fundamental organizational models in computer science that arrange and store data elements in a linear sequence, where each element has a predecessor and a successor, except for the first and last elements, respectively. These structures facilitate straightforward access, insertion, and deletion operations, making them essential components in algorithmic design, data storage, and various computing applications. Some examples of linear data structures are Arrays, Linked List, Stack etc.
Array Data Structure
An array is a fundamental and versatile data structure used in computer science for storing and organizing elements of the same type. It provides a contiguous block of memory locations to store a fixed-size sequence of elements, each identified by an index or a key. Arrays are widely employed in various algorithms and applications due to their efficiency, simplicity, and predictable access patterns.

Arrays can be one-dimensional or multi-dimensional, catering to different use cases. A one-dimensional array is essentially a linear list, while multi-dimensional arrays extend this concept to multiple dimensions, forming matrices or higher-dimensional structures. Multi-dimensional arrays are beneficial for representing complex data structures, such as tables and matrices, facilitating the organization of data in a structured and efficient manner.
Queue Data Structure
A queue is a fundamental data structure that follows the First In, First Out (FIFO) principle, where the first element added to the queue is the first one to be removed. This structure is akin to a real-world queue, such as people waiting in line at a supermarket checkout. Queues find widespread use in computer science, playing a crucial role in various algorithms, simulations, and system designs.

The defining characteristic of a queue is its sequential ordering of elements. New elements are added at the rear, and removal occurs from the front, maintaining a consistent order. This ensures that the oldest element in the queue is always the next to be processed, making queues particularly useful in scenarios where order preservation is critical.
Stack Data Structure
The stack is a fundamental data structure that follows the Last In, First Out (LIFO) principle, where the last element added is the first one to be removed. It operates much like a stack of plates, with the most recently placed plate being the first to be taken off. This intrinsic property makes stacks a powerful and versatile tool in computer science, finding applications in algorithmic design, memory management, and parsing expressions.
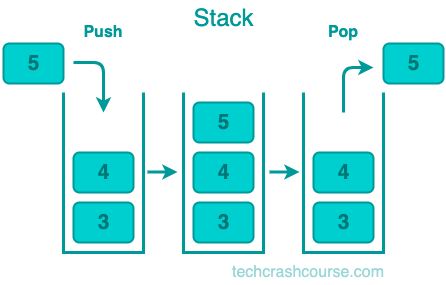
One of the defining characteristics of a stack is its sequential ordering of elements. New elements are added or "pushed" onto the top of the stack, and removal or "pop" operations occur from the top as well. This ensures that the last item added is the first to be processed, making stacks particularly useful in scenarios where the order of operations is critical.
Linked List Data Structure
A linked list is a linear collection of elements, known as nodes, where each node contains data and a reference or link to the next node in the sequence. This structure allows for efficient insertions and deletions at any position within the list without the need for contiguous memory allocation, a characteristic that sets linked lists apart from arrays.
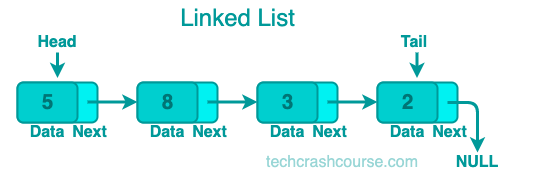
The linked list's dynamic nature is particularly advantageous in scenarios where the size of the data structure is unknown or subject to change. Dynamic memory allocation allows for efficient use of memory, as nodes can be allocated or deallocated as needed. This contrasts with arrays, which have a fixed size and may lead to memory inefficiencies when resizing is required.
Non-Linear Data Structure
Non-linear data structures deviate from the sequential organization of linear structures, allowing for more complex relationships between data elements. Unlike linear structures, non-linear structures enable representation of hierarchical, interconnected, or more arbitrary relationships among elements. These data structures play a crucial role in modeling real-world scenarios, optimizing certain types of operations, and providing efficient solutions to various computational problems.
Non-linear data structures offer diverse solutions to a wide range of computational challenges. Their flexibility in modeling complex relationships and optimizing specific operations makes them indispensable in various domains of computer science.
Tree Data Structure
The tree data structure is a hierarchical and versatile organizational model widely used in computer science for representing relationships and hierarchies among elements. With its branching structure, the tree provides an efficient way to store and retrieve information, making it a fundamental building block for various applications, algorithms, and data structures.

A tree consists of nodes connected by edges, forming a directed, acyclic graph. The topmost node, known as the root, serves as the starting point for traversing the tree. Each node can have child nodes, forming branches, and nodes without children are termed leaves. Nodes with a common parent are considered siblings.
Graph Data Structure
The graph data structure is a fundamental abstraction in computer science, representing a collection of nodes or vertices connected by edges. Graphs provide a flexible and powerful framework for modeling relationships and connections between various entities. They play a pivotal role in diverse applications, ranging from social networks and transportation systems to algorithmic problem-solving and data analysis.

At its core, a graph is a collection of vertices, or nodes, and edges that connect pairs of vertices. The arrangement of these nodes and edges can vary, giving rise to different types of graphs. A simple graph has at most one edge between any pair of vertices, while a multigraph can have multiple edges between the same pair of vertices. Directed graphs, or digraphs, introduce the concept of edges having a direction, and weighted graphs assign numerical values to edges, representing weights or costs.
Trie Data Structure
The trie data structure, short for retrieval tree or digital tree, is a specialized tree-like structure that is particularly efficient for storing and retrieving strings. Unlike traditional tree structures where each node represents a single character, a trie node represents a partial or complete string. Tries excel in scenarios where quick string matching, prefix search, and dictionary implementations are crucial.

At its core, a trie is an ordered tree data structure where each node represents a single character of the stored strings. The structure allows for fast search and retrieval operations as the path from the root to a particular node spells out the associated string. Trie nodes typically store additional information, such as whether the node represents the end of a complete string, making trie traversal straightforward and efficient.
One notable feature of tries is their ability to share common prefixes among stored strings. This significantly reduces the memory footprint compared to other data structures, such as hash tables or binary search trees. This space efficiency is particularly valuable when dealing with large datasets or dictionaries.
Tries find widespread use in applications where string-related operations are prevalent. Spell checkers utilize tries to efficiently suggest corrections or completions based on user input. Autocomplete functionality in search engines and text editors benefits from the rapid prefix search capabilities of tries.