

Singly Linked List
A Singly Linked List is a linear data structure in which each element called a node, contains two parts, the data and a reference to the next node in the sequence. The reference to the next node is called a pointer or a link.
Each node only stores the address of its successor node and not its predecessor. The last node in the list contains a null pointer, indicating the end of the list. Unlike arrays, linked lists do not require contiguous memory allocation, allowing for flexible size adjustments during runtime.
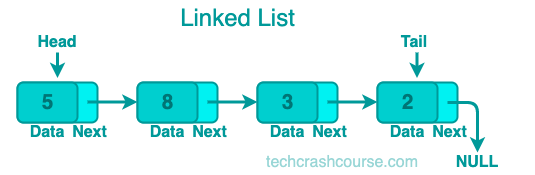
Representation of a Singly Linked List
A singly linked list is a linear data structure where elements, known as nodes, are connected in a sequential order. Each node contains data and a reference (link) to the next node in the sequence. The last node typically points to null, indicating the end of the list. In this structure, each node contains two fields:
- Data: This field stores the value of the node.
- Link: This field contains the memory address of the next node in the list.
// Define a Node structure to hold a value and
// a pointer to the next node
struct Node {
int value;
struct Node* next;
};
Key concepts of singly linked lists:
- Node : The basic building block containing data and a reference to the next node.
- Head : The starting point of the list, representing the first node.
- Tail : The last node in the list, where the reference points to null.
- Null : The reference in the last node, indicating the end of the list.
Uses of Singly Linked List
Singly Linked List data structure is commonly used in situations where data needs to be stored and accessed in a sequential manner, but the size of the data is not known in advance. Some common use cases of linked list include:
- Implementing dynamic data structures such as stacks, queues, and hash tables.
- Implementing graph algorithms such as topological sort, Dijkstra's shortest path, and minimum spanning tree algorithms.
- Managing memory in operating systems and programming languages.
Advantages and Disadvantages of Singly Linked List
Advantages of Singly Linked List
- Dynamic size: The size of a linked list can be changed dynamically, unlike arrays, which have a fixed size.
- Easy insertion and deletion: Singly Linked List allows easy insertion and deletion of nodes, as only the pointers need to be modified.
- Efficient memory utilization: Singly Linked List allows efficient memory utilization as nodes can be allocated as needed.
Disadvantages of Singly Linked List
- No random access: Singly Linked List does not allow for random access of elements like arrays, as it requires sequential traversal from the head node. Accessing elements in a linked list requires traversing the list sequentially, making random access less efficient compared to arrays. Unlike arrays, which offer constant-time access to elements based on an index, linked lists require O(n) time for access, where n is the position of the element.
- Extra memory overhead: Singly Linked List requires extra memory to store the link field for each node.
Common Singly Linked List Operations
Add a Node in a Singly Linked List
To add a node to a Singly Linked List, we first create a new node and assign its data field with the value we want to store. We then update the link field of the new node to point to the current head node, and update the head node to point to the new node.
void addNode(int value) {
Node *newNode = (Node*)malloc(sizeof(Node));
newNode->data = value;
newNode->next = head;
head = newNode;
}
Traverse a Singly Linked List
To traverse a Singly Linked List, we start at the head node and follow the link field of each node until we reach the end of the list (the node with a null pointer).
void traverse() {
Node *current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
}
Delete a Node from a Singly Linked List
To delete a node from a Singly Linked List, we need to find the node to delete and update the link field of the previous node to point to the next node. We then free the memory of the deleted node.
void deleteNode(int value) {
Node *current = head;
Node *previous = NULL;
// Traverse the list to find the node to delete
while (current != NULL && current->data != value) {
previous = current;
current = current->next;
}
// If the node to delete is found, update the link field of the previous node
if (current != NULL) {
if (previous == NULL) {
head = current->next;
} else {
previous->next = current->next;
}
free(current);
}
}
Search an Element in Singly Linked List
To search for an element in a Singly Linked List, we start at the head node and traverse the list until we find the node with the desired value, or reach the end of the list.
bool search(int value) {
Node *current = head;
while (current != NULL) {
if (current->data == value) {
return true;
}
current = current->next;
}
return false;
}
Singly Linked List Operations Time Complexity
- Add a node to the beginning: O(1)
- Traverse the list: O(n)
- Delete a node: O(n)
- Search an element: O(n)
Singly Linked List Implementation Program
Now that we have an understanding of the Singly Linked List data structure and its operations, let's look at how to implement a Singly Linked List in C.
#include <stdio.h>
#include <stdlib.h>
// Define a Node structure to hold a value and a pointer to the next node
struct Node {
int value;
struct Node* next;
};
// Define the head of the Linked List
struct Node* head = NULL;
// Add a node to the Linked List
void addNode(int value) {
// Allocate memory for a new node
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));
// Set the value and next pointer of the new node
newNode->value = value;
newNode->next = NULL;
// If the Linked List is empty, set the head to the new node
if (head == NULL) {
head = newNode;
return;
}
// Traverse to the end of the Linked List
struct Node* current = head;
while (current->next != NULL) {
current = current->next;
}
// Set the next pointer of the last node to the new node
current->next = newNode;
}
// Traverse the Linked List and print each value
void traverse() {
struct Node* current = head;
while (current != NULL) {
printf("%d ", current->value);
current = current->next;
}
printf("\n");
}
// Delete a node from the Linked List with the specified value
void deleteNode(int value) {
// If the head node contains the value, delete it and set the head to the next node
if (head->value == value) {
struct Node* temp = head;
head = head->next;
free(temp);
return;
}
// Traverse the Linked List to find the node with the value
struct Node* current = head;
while (current->next != NULL && current->next->value != value) {
current = current->next;
}
// If the node is not found, print an error message and return
if (current->next == NULL) {
printf("Error: %d not found in Linked List\n", value);
return;
}
// Delete the node and set the next pointer of the previous node to the next node
struct Node* temp = current->next;
current->next = current->next->next;
free(temp);
}
// Search the Linked List for a node with the specified value
void search(int value) {
struct Node* current = head;
while (current != NULL && current->value != value) {
current = current->next;
}
if (current == NULL) {
printf("%d not found in Linked List\n", value);
} else {
printf("%d found in Linked List\n", value);
}
}
int main() {
// Create a Linked List with nodes containing values 3, 7, 1, and 9
addNode(3);
addNode(7);
addNode(1);
addNode(9);
// Print the initial state of the Linked List
printf("Initial Linked List: ");
traverse();
// Demonstrate deleting a node with value 1
deleteNode(1);
printf("Linked List after deleting 1: ");
traverse();
// Demonstrate searching for a node with value 7
search(7);
// Clean up memory by deleting all nodes in the Linked List
struct Node* current = head;
struct Node* temp;
while (current != NULL) {
temp = current;
current = current->next;
free(temp);
}
head = NULL;
return 0;
}
Output
Initial Linked List: 3 7 1 9 Linked List after deleting 1: 3 7 9 7 found in Linked List
This program first creates a Linked List with nodes containing values 3, 7, 1, and 9 by calling the addNode() function four times. It then prints the initial state of the Linked List by calling the traverse() function.
Next, it demonstrates deleting a node with value 1 by calling the deleteNode() function with an argument of 1. It then prints the updated state of the Linked List by calling the traverse() function again.
Finally, it demonstrates searching for a node with value 7 by calling the search() function with an argument of 7. It cleans up memory by deleting all nodes in the Linked List and setting the head to NULL.
Conclusion
Singly linked lists are versatile data structures with various applications. They provide efficient dynamic memory allocation, making them suitable for scenarios where the size of the data is not known in advance. In the context of hash tables, singly linked lists offer an effective solution for collision resolution through chaining. Understanding the basic operations, implementation details, and the integration of singly linked lists with hash tables allows developers to leverage this data structure effectively. While singly linked lists offer advantages in terms of dynamic sizing and efficient insertion/deletion, it's crucial to consider their limitations, such as sequential access and additional memory overhead, when choosing the appropriate data structure for a given application.